What certifications are available for Site Reliability Engineers?
Site Reliability Engineers (SREs) pursue certifications in cloud platforms (AWS, GCP, Azure), Kubernetes (CKA, CKAD), and observability platforms (Datadog, Prometheus). Google Cloud offers a Professional Cloud DevOps Engineer certification that most closely aligns with SRE principles including SLOs, error budgets, monitoring, and reliability architecture.
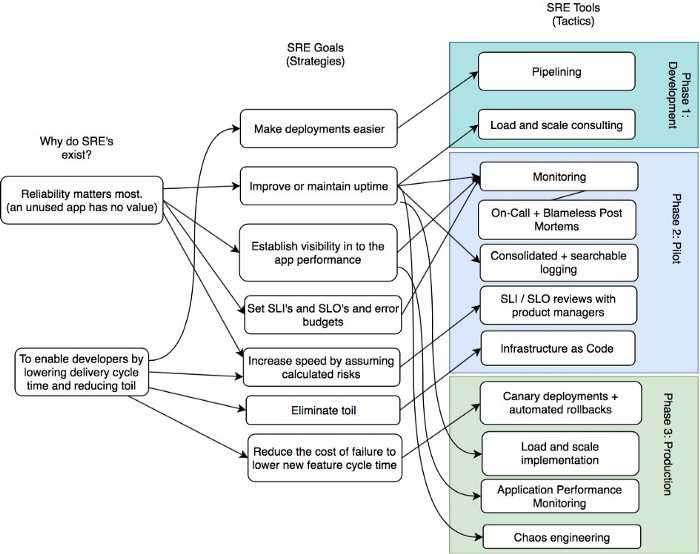
The Site Reliability Engineering (SRE) discipline was created by Google to apply software engineering principles to operations work, replacing traditional IT operations with scalable, automated, and measurable reliability practices. SRE roles are among the highest-compensated in the technology industry, with senior SRE salaries regularly exceeding $200,000 USD at major technology companies.
SREs bridge the gap between software development and operations by defining reliability as a feature, measuring it through Service Level Objectives (SLOs), and using error budgets to balance reliability with the pace of innovation. The primary SRE certification pathways focus on Google Cloud's Professional Cloud DevOps Engineer exam, supplemented by Kubernetes, observability, and chaos engineering knowledge.
Certification Pathways for SREs
| Certification | Provider | Cost | Most Relevant SRE Topics |
|---|---|---|---|
| Professional Cloud DevOps Engineer | Google Cloud | $200 | SLOs, CI/CD, monitoring, reliability |
| Certified Kubernetes Administrator | CNCF/LF | $395 | Container orchestration, production Kubernetes |
| Datadog Fundamentals | Datadog | Free | Observability, APM, dashboards |
| Prometheus Certified Associate | CNCF/LF | $250 | Metrics, alerting, PromQL |
| Chaos Engineering Practitioner | Chaos Toolkit | Varies | Chaos experiments, resilience testing |
| AWS SysOps Administrator | AWS | $300 | Cloud operations, automation, monitoring |
Core SRE Concepts
Service Level Objectives (SLOs)
SLOs define the reliability targets for a service. They are the foundation of the SRE error budget model:
SLI (Service Level Indicator): A quantitative measure of some aspect of service quality.
# Common SLIs:
Availability SLI = (Successful requests / Total requests) * 100
Latency SLI = Percentage of requests completing under 200ms
Error rate SLI = (Error responses / Total responses)
SLO (Service Level Objective): The target value for an SLI:
Availability SLO: 99.9% of requests succeed
Latency SLO: 95% of requests complete within 200ms
Error rate SLO: Error rate below 0.1%
SLA (Service Level Agreement): The contractual commitment to customers, typically less aggressive than the internal SLO:
| Metric | Internal SLO | External SLA |
|---|---|---|
| Availability | 99.9% | 99.5% |
| Latency p95 | 200ms | 500ms |
| Error rate | 0.1% | 0.5% |
"The most important SRE principle is that 100% reliability is the wrong target. If you have 100% uptime, you're not moving fast enough. The error budget — the gap between perfect reliability and your SLO — is exactly the amount of unreliability you can afford to spend on new features and changes." -- Google SRE Handbook
Error Budgets
The error budget is the allowed amount of unreliability defined by the SLO:
Error Budget = 1 - SLO
For 99.9% SLO:
Error budget = 0.1% of requests (or time)
Monthly error budget = 0.001 * 30 days * 24 hours * 60 minutes = 43.2 minutes/month
Error budget policy:
- When error budget is healthy: Deploy features at normal velocity
- When error budget is 50% consumed: Increase testing rigor, slow deployments
- When error budget is exhausted: Freeze non-critical deployments, focus on reliability
Observability and Monitoring
The Three Pillars of Observability
Metrics: Numeric time-series data (Prometheus, Datadog, CloudWatch):
# Prometheus recording rule for availability SLI
groups:
- name: availability
rules:
- record: job:request_success_ratio:rate5m
expr: |
sum(rate(http_requests_total{status!~"5.."}[5m])) by (job)
/
sum(rate(http_requests_total[5m])) by (job)
Logs: Discrete events with structured data (Elasticsearch, CloudWatch Logs, Loki):
{
"timestamp": "2025-01-15T10:30:00Z",
"level": "ERROR",
"service": "payment-service",
"trace_id": "abc-123",
"message": "Payment processing failed",
"error_code": "INSUFFICIENT_FUNDS",
"user_id": "user-456",
"latency_ms": 245
}
Traces: Distributed request flows across services (Jaeger, Zipkin, AWS X-Ray, Tempo):
Request: checkout → payment-service → bank-api → fraud-detection
├── checkout [0-50ms]
│ ├── validate cart [5-15ms]
│ └── call payment-service [15-50ms]
│ ├── call bank-api [20-40ms]
│ │ └── HTTP POST /authorize [22-38ms]
│ └── call fraud-detection [30-45ms]
│ └── ML scoring [32-44ms]
└── [response returned]
SLO Monitoring with Prometheus
# SLO alerting with multi-window, multi-burn-rate alerts
groups:
- name: slo-alerts
rules:
# Page immediately: burning 14.4x faster (1-hour window)
- alert: SLOBurnRateHigh
expr: |
(
job:request_success_ratio:rate1h < (1 - 14.4 * 0.001)
and
job:request_success_ratio:rate5m < (1 - 14.4 * 0.001)
)
labels:
severity: critical
annotations:
summary: "High error burn rate - SLO at risk"
# Ticket: burning 6x faster (6-hour window)
- alert: SLOBurnRateMedium
expr: |
job:request_success_ratio:rate6h < (1 - 6 * 0.001)
labels:
severity: warning
annotations:
summary: "Elevated error rate - monitor closely"
PromQL Fundamentals
PromQL (Prometheus Query Language) is essential for SRE monitoring work:
# Request rate per service (5-minute window)
rate(http_requests_total[5m])
# Error rate percentage by service
100 * (
sum(rate(http_requests_total{status=~"5.."}[5m])) by (service)
/
sum(rate(http_requests_total[5m])) by (service)
)
# 95th percentile latency
histogram_quantile(0.95,
rate(http_request_duration_seconds_bucket[5m])
)
# Availability over the last 30 days (for SLO reporting)
avg_over_time(
job:request_success_ratio:rate5m[30d]
)
Reliability Engineering
Toil Reduction
Toil is manual, repetitive, automatable work that scales with service load. Google SRE guidance limits toil to less than 50% of an SRE's time:
Identifying toil:
- Manual interventions during incidents (restarting services, clearing queues)
- Repetitive deployment steps that could be automated
- Manual capacity planning and scaling
- Certificate renewals performed manually
Toil elimination strategy:
- Identify and measure toil (track time spent on each category)
- Prioritize automation projects by toil volume
- Build automation (runbooks → scripts → self-healing systems)
- Measure reduction in toil after automation
Capacity Planning
Load testing validates capacity before production traffic:
# k6 load test - ramp to 1000 VUs
k6 run --vus 10 --duration 30s --ramp-vus 1000 load-test.js
# Locust load test
locust -f locustfile.py --headless -u 1000 -r 100 \
--host https://myapp.com --run-time 300s
Capacity planning model:
Current peak load: 5000 req/s
Current CPU at peak: 70%
CPU headroom target: 40% (allow 60% utilization for safety)
Growth rate: 20% monthly
Capacity needed in 3 months:
5000 * (1.2)^3 = 8640 req/s
Current capacity: 5000 / 0.7 * 0.6 = 4286 req/s (at 60% utilization)
Capacity gap: 8640 - 4286 = 4354 req/s additional needed
Chaos Engineering
Chaos engineering proactively tests resilience by injecting controlled failures:
Chaos experiment process:
- Hypothesize: "If a database replica fails, the application will automatically failover within 30 seconds and availability will remain above 99.5%"
- Define steady state: Baseline metrics before experiment
- Introduce failure: Kill a database replica, inject latency, terminate pods
- Observe: Compare actual behavior vs. hypothesis
- Learn and fix: Close gaps between expected and actual resilience
# Chaos Mesh - inject pod failure
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: pod-failure-test
spec:
action: pod-kill
mode: one
selector:
namespaces: [production]
labelSelectors:
app: payment-service
scheduler:
cron: "@every 10m"
Incident Management
Incident Response Roles
| Role | Responsibility |
|---|---|
| Incident Commander (IC) | Coordinates response, makes decisions, manages communication |
| Technical Lead | Drives technical investigation and remediation |
| Communications Lead | Stakeholder updates, customer communications |
| Scribe | Documents timeline, decisions, and actions taken |
Incident Severity Levels
| Severity | Impact | Response Time | Examples |
|---|---|---|---|
| SEV-1 | Critical (outage) | Immediate | Complete service down, data loss |
| SEV-2 | Major degradation | 15 minutes | >20% of users impacted |
| SEV-3 | Minor degradation | 2 hours | <20% of users impacted, workaround exists |
| SEV-4 | No user impact | Next business day | Monitoring gap, technical debt |
Blameless Postmortems
Postmortems are written analyses of incidents focused on systemic improvements rather than individual blame:
Postmortem structure:
- Summary: One-paragraph description of the incident and impact
- Timeline: Chronological sequence of events from detection to resolution
- Root cause analysis: Five Whys or fault tree analysis
- Impact: Duration, affected users, financial cost
- Action items: Specific, assigned, time-bound improvements
- Lessons learned: What worked well, what to improve
"The goal of a postmortem is not to find someone to blame. It is to understand the systemic conditions that made the failure possible so we can remove those conditions. Any failure that could happen once can happen again unless the system is changed." -- Google SRE Workbook, Chapter 9
Frequently Asked Questions
Is there a dedicated SRE certification from Google or DORA? There is no official "SRE certification" from Google or DORA. The Google Cloud Professional Cloud DevOps Engineer certification is the closest aligned to SRE principles, covering SLOs, monitoring, CI/CD reliability, and deployment strategies. DORA (DevOps Research and Assessment) offers assessments and research rather than certifications. Most SRE practitioners demonstrate expertise through Kubernetes certifications, cloud platform expertise, and demonstrated experience managing production services.
What programming languages should an SRE know? Python is the most commonly used language for SRE automation, scripting, and tooling. Go is increasingly popular for writing Kubernetes operators, controllers, and high-performance tools. Bash remains essential for shell scripting and quick automation. SQL is needed for querying monitoring data and databases. Strong SREs are language-agnostic but typically have deep fluency in at least Python and Bash, with growing Go proficiency.
How is SRE different from DevOps? SRE is a specific implementation of DevOps principles with a quantitative focus on reliability. DevOps is a broader cultural and organizational movement emphasizing collaboration between development and operations. SRE uses specific practices — SLOs, error budgets, toil measurement, and reliability engineering — to operationalize DevOps goals. Google coined SRE; DevOps evolved from the broader industry. Many organizations practice DevOps philosophies without explicitly running SRE teams.
References
- Beyer, B., Jones, C., Petoff, J., & Murphy, N. (2016). Site Reliability Engineering: How Google Runs Production Systems. O'Reilly Media.
- Beyer, B., Murphy, N., Rensin, D., Kawahara, K., & Thorne, S. (2018). The Site Reliability Workbook. O'Reilly Media.
- Google Cloud. (2025). Professional Cloud DevOps Engineer Certification. https://cloud.google.com/certifications/cloud-devops-engineer
- DORA. (2024). Accelerate State of DevOps Report. https://dora.dev/
- Rosenthal, C., & Jones, N. (2020). Chaos Engineering. O'Reilly Media.
- Prometheus Authors. (2025). Prometheus Documentation. https://prometheus.io/docs/
Frequently Asked Questions
What certifications are available for Site Reliability Engineers?
Site Reliability Engineers pursue certifications in cloud platforms (AWS, GCP, Azure), Kubernetes (CKA, CKAD), and observability platforms (Datadog, Prometheus). Google Cloud offers a Professional Cloud DevOps Engineer certification that most closely aligns with SRE principles including SLOs, error budgets, monitoring, and reliability architecture.
Is there a dedicated SRE certification from Google or DORA?
There is no official SRE certification from Google or DORA. The Google Cloud Professional Cloud DevOps Engineer certification is the closest aligned to SRE principles. Most SRE practitioners demonstrate expertise through Kubernetes certifications, cloud platform expertise, and demonstrated experience managing production services.
How is SRE different from DevOps?
SRE is a specific implementation of DevOps principles with a quantitative focus on reliability using SLOs, error budgets, toil measurement, and reliability engineering. DevOps is a broader cultural movement emphasizing collaboration between development and operations. Google coined SRE; DevOps evolved from the broader industry.